Kafka(Go)系列(一)---初识 Kafka 架构和基本概念
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。
初识kafka架构
Kafka的整体架构有三部分组成,分别是 Producer、Broker、Consumer
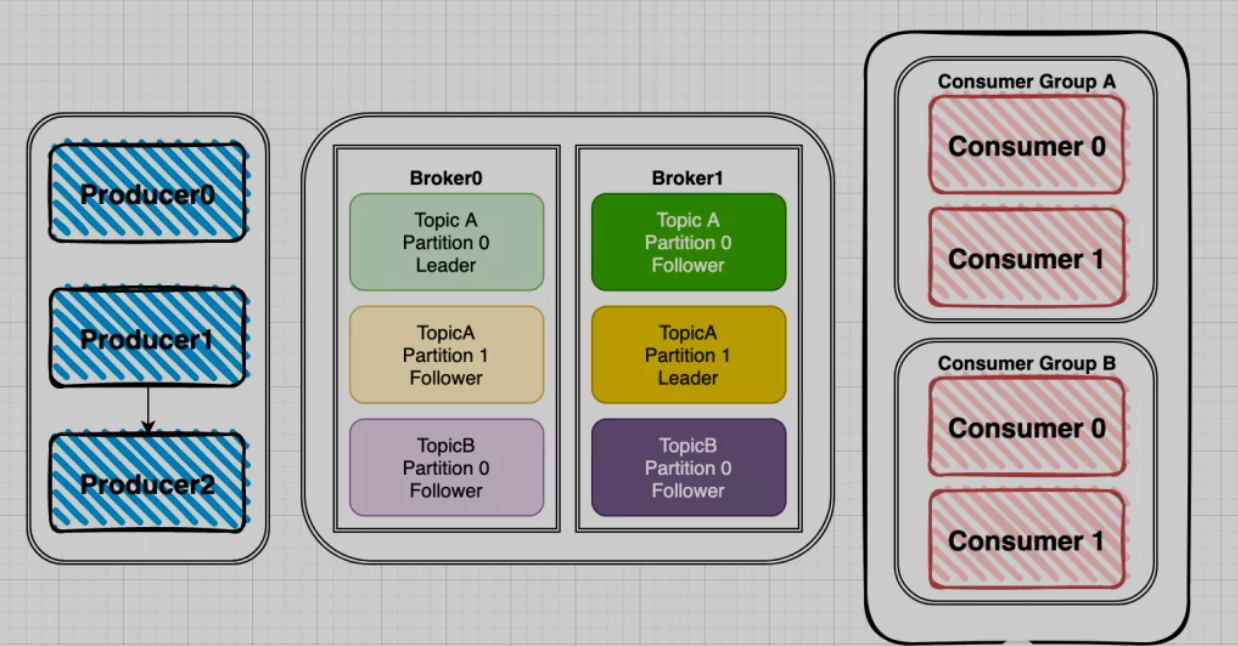
针对这张图来介绍一下各个部分。
- Producer:数据的生产者,可以将数据发布到所选择的
topic中。 - Broker:消息中间处理和存储节点(服务器),一个节点就是一个broker,一个Kafka集群由一个或多个broker组成。
- Consumer:数据的消费者,可以根据一定的顺序消费topic中的消息。也可以由多个Consumer组成的Consumer Group进行多消费者消费,在
topic中的每条记录都会被分配给订阅消费组中的一个(仅一个)消费者实例,消费者实例可以分布在多个进程中或者多台机器上。
其他概念
- topic:可以理解为一个消息的集合,topic存储在broker中,一个topic可以有多个partition分区,一个topic可以有多个Producer来push消息,一个topic可以有多个消费者向其pull消息,一个topic可以存在一个或多个broker中。
- Partition:其是topic的子集,不同分区分配在不同的broker上进行水平扩展从而增加kafka并行处理能力,同topic下的不同分区信息是不同的,同一分区信息是有序的,可以理解为topic消息散列到不同的分区;每一个分区都有一个或者多个副本,其中会选举一个
leader,fowller从leader拉取数据更新自己的log(每个分区逻辑上对应一个log文件夹),消费者向leader中pull信息。
生产者push消息与消息分区
-
producer先从kafka集群找到该partition的leader
-
producer将消息发送给leader,leader将该消息写入本地
-
follwers从leader pull消息,写入本地log后leader发送ack
-
leader 收到所有 ISR 中的 replica 的 ACK 后,增加high watermark,并向 producer 发送 ack
通过这个流程我们可以看到kafka最终会返回一个ack来确认推送消息结果,这里kafka提供了三种模式:
NoResponse RequiredAcks = 0:这个代表的就是数据推出的成功与否都与我无关了,WaitForLocal RequiredAcks = 1:当local(leader)确认接收成功后,就可以返回给Producer确认ack了WaitForAll RequiredAcks = -1:当所有的leader和follower都接收成功时,才会返回ack
如果我们选择了模式1,这种模式丢失数据的几率很大,无法重试。
如果我们选择了模式2,这种模式下只要leader不挂,就可以保证数据不丢失,但是如果leader挂了,follower还没有同步数据,那么就会有一定几率造成数据丢失。
如果选择了模式3,这种情况不会造成数据丢失,但是有可能会造成数据重复,假如leader与follower同步数据是网络出现问题,就有可能造成数据重复的问题。
所以在生产环境中我们可以选择模式2或者模式3来保证消息的可靠性,具体需要根据业务场景来进行选择,在乎吞吐量就选择模式2,不在乎吞吐量,就选择模式3,要想完全保证数据不丢失就选择模式3是最可靠的。
生产时消息分区
org.apache.kafka.clients.producer.internals.DefaultPartitioner
The default partitioning strategy:
- If a partition is specified in the record, use it
- If no partition is specified but a key is present choose a partition based on a hash of the key
- If no partition or key is present choose a partition in a round-robin fashion
默认的分区策略是:
- 如果在发消息的时候指定了分区,则消息投递到指定的分区
- 如果没有指定分区,但是消息的key不为空,则基于key的哈希值来选择一个分区
- 如果既没有指定分区,且消息的key也是空,则用轮询的方式选择一个分区
消费者pull消息与分区消费
push消息时会把数据追加到Partition并且分配一个偏移量,这个偏移量代表当前消费者消费到的位置,通过这个Partition也可以保证消息的顺序性,消费者在pull到某个消息后,可以设置自动提交或者手动提交commit,提交commit成功,offset就会发生偏移。
所以自动提交会带来数据丢失的问题,手动提交会带来数据重复的问题,分析如下:
- 在设置自动提交的时候,当我们拉取到一个消息后,此时offset已经提交了,但是我们在处理消费逻辑的时候失败了,这就会导致数据丢失了
- 在设置手动提交时,如果我们是在处理完消息后提交commit,那么在commit这一步发生了失败,就会导致重复消费的问题。
比起数据丢失,重复消费是符合业务预期的,我们可以通过一些幂等性设计来规避这个问题。
消费时消息分区
消费者以组的名义订阅主题,主题有多个分区,消费者组中有多个消费者实例,那么消费者实例和分区之前的对应关系是怎样的呢?
换句话说,就是组中的每一个消费者负责那些分区,这个分配关系是如何确定的呢?
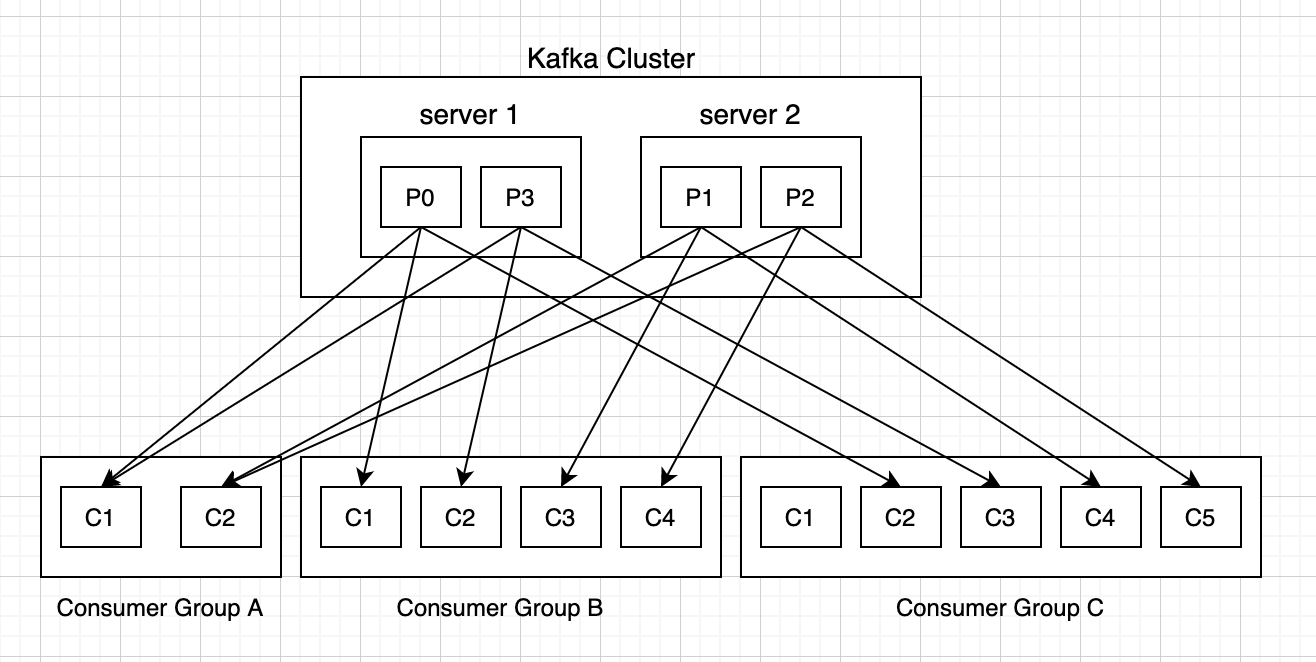
同一时刻,一条消息只能被组中的一个消费者实例消费
消费者组订阅这个主题,意味着主题下的所有分区都会被组中的消费者消费到,如果按照从属关系来说的话就是,主题下的每个分区只从属于组中的一个消费者,不可能出现组中的两个消费者负责同一个分区。
那么,问题来了。
如果分区数大于或者等于组中的消费者实例数?那自然没有什么问题,无非一个消费者会负责多个分区,(PS:当然,最理想的情况是二者数量相等,这样就相当于一个消费者负责一个分区)。
如果消费者实例的数量大于分区数?那么按照默认的策略,有一些消费者是多余的,一直接不到消息而处于空闲状态。(PS:之所以强调默认策略是因为你也可以自定义策略)
话又说回来,假设多个消费者负责同一个分区,那么会有什么问题呢?
我们知道,Kafka它在设计的时候就是要保证分区下消息的顺序,也就是说消息在一个分区中的顺序是怎样的,那么消费者在消费的时候看到的就是什么样的顺序,那么要做到这一点就首先要保证消息是由消费者主动拉取的,其次还要保证一个分区只能由一个消费者负责。倘若,两个消费者负责同一个分区,那么就意味着两个消费者同时读取分区的消息,由于消费者自己可以控制读取消息的offset,就有可能C1才读到2,而C2读到1,C1还没处理完,C2已经读到3了,则会造成很多浪费,因为这就相当于多线程读取同一个消息,会造成消息处理的重复,且不能保证消息的顺序,这就跟主动推送无异。
- 原文作者:devhg
- 原文链接:https://ihui.ink/post/kafka/00-kafka-know/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。