ES系列(一)---分布式增删查改过程原理
关于数据是如何在es集群中分布和获取的相关技术细节。这种使用和细节分离是刻意为之的——你不需要知道数据在Elasticsearch如何分布它就会很好的工作。
注意:
下面的信息只是出于兴趣阅读,你不必为了使用Elasticsearch而弄懂和记住所有的细节。讨论的这些选项只提供给高级用户。
阅读这一部分只是让你了解下系统如何工作,并让你知道这些信息以备以后参考,所以不要被细节吓到。
1. 什么是分片
为了将数据添加到Elasticsearch,我们需要索引**(index)**——一个存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片**(shards)**逻辑命名空间。
一个分片**(shard)**是一个最小级别**“**工作单元**(worker unit)”**,它只是保存索引中所有数据的一小片。在接下来的文章,我们将详细说明分片的工作原理,但是现在只要知道分片是一个**单一的Lucene实例**即可,并且它本身就是一个完整的搜索引擎。我们的文档存储和被索引在分片中,但是我们的程序不知道如何直接与它们通信。取而代之的是,他们直接与索引通信。
分片用于Elasticsearch集群中分配数据。想象把分片当作数据的容器。文档存储在分片中,然后分片分布在集群中的节点上。当你的集群扩容或缩小,Elasticsearch将会自动在你的节点间迁移分片数据,以使集群保持平衡。
分片可以是主分片**(primary shard)**或者复制分片**(replica shard)**。你索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了你最多能存储多少数据。复制分片只是主分片的一个副本,它用于提供数据的冗余副本,在硬件故障之后提供数据容灾保护,同时服务于像搜索和检索等只读请求。
主分片的数量会在其索引创建完成后修正,之后不能修改,但是复制分片的数量会随时变化。一个索引默认指派5个主分片。
例如:我们只指派3个主分片和一个复制分片(每个主分片有一个复制分片对应):
|
|
2. 路由文档到分片
当你索引一个文档,它被存储在单独一个主分片上。Elasticsearch是如何知道文档属于哪个分片的呢?
他根据简单的算法计算得出,routing默认是_id
shard = hash(routing) % number_of_primary_shards
这也解释了为什么主分片的数量只能在创建索引时定义且不能修改。如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
有时用户认为固定数量的主分片会让之后的扩展变得很困难。现实中,有些技术会在你需要的时候让扩展变得容易。【留坑】
所有的文档API( get 、 index 、 delete 、 bulk 、 update 、 mget )都接收一个 routing 参数,它用来自定义文档到分片的映射。自定义路由值可以确保所有相关文档——例如属于同一个人的文档被保存在同一分片上。
3. 主分片和复制分片如何交互
我们能够发送请求给集群中任意一个节点。每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。具体会在下面分析。
4. 新建、索引和删除文档
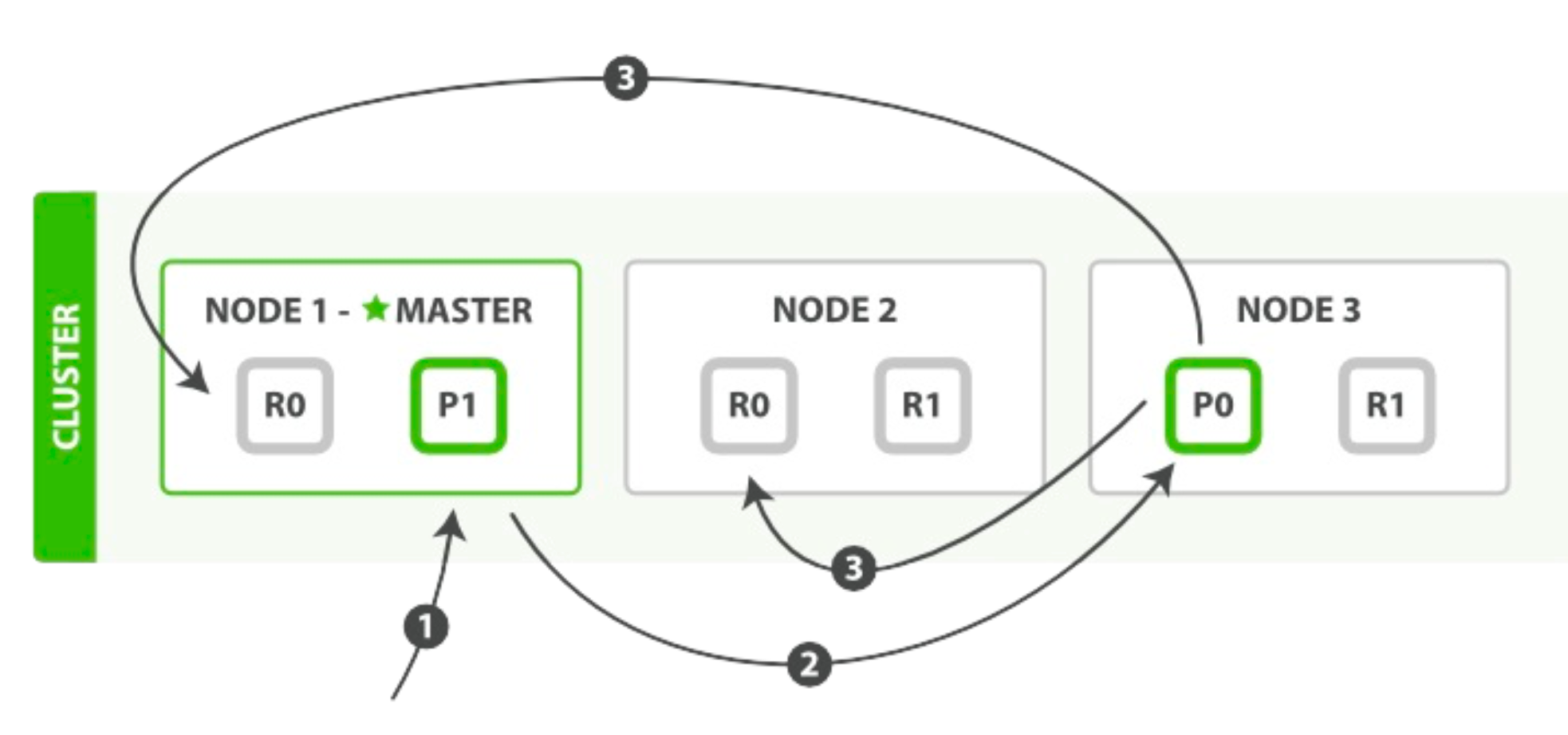
在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
-
客户端给 Node 1 发送新建、索引或删除请求。
-
节点使用文档的
_id(默认)确定文档属于分片 0 。Node 1 转发请求到 Node 3 ,分片 0 位于这个节点上。 -
Node 3 在主分片上执行请求,如果成功,它转发请求到相应的位于 Node 1 和 Node 2 的副本分片上。当所有的副本分片
执行成功, Node 3 报告成功到请求的节点,请求的节点再报告给客户端。
-
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了。
有很多可选的请求参数允许你更改这一过程。你可能想牺牲一些数据可靠性来提高性能。这一选项很少使用因为Elasticsearch已经足够快,不过为了内容的完整我们将做一些阐述。
replication
- sync 。默认配置,这将导致主分片得到复制分片的成功响应后才返回。
- async 。请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。
async这个选项不建议使用。默认的 sync 复制允许Elasticsearch强制反馈传输。 async 复制可能会因为在不等待其它分片就绪的情况下,有过多的请求而使Elasticsearch过载。
consistency
- one。只有一个分片。
- all。所有的主分片和副本分片。
- quorum。默认配置,达到quorum数值或过半分片。
默认主分片在尝试写入时需要规定数量quorum或过半的分片可用。这是防止数据被写入到错的网络分区。规定的数量计算公式如下:
int((primary + number_of_replicas) / 2) + 1
注意 number_of_replicas 是在索引中的的设置,用来定义复制分片的数量,而不是现在活动的复制节点的数量。如果你定义 了索引有3个复制节点,那规定数量是:
int((primary + 3 replicas) / 2) + 1 = 3
timeout
当分片副本不足时会怎样?Elasticsearch会等待更多的分片出现。默认等待一分钟。如果需要,你可以设置 timeout 参数让它终止的更早: 100 表示100毫秒, 30s 表示30秒。
5. 检索文档
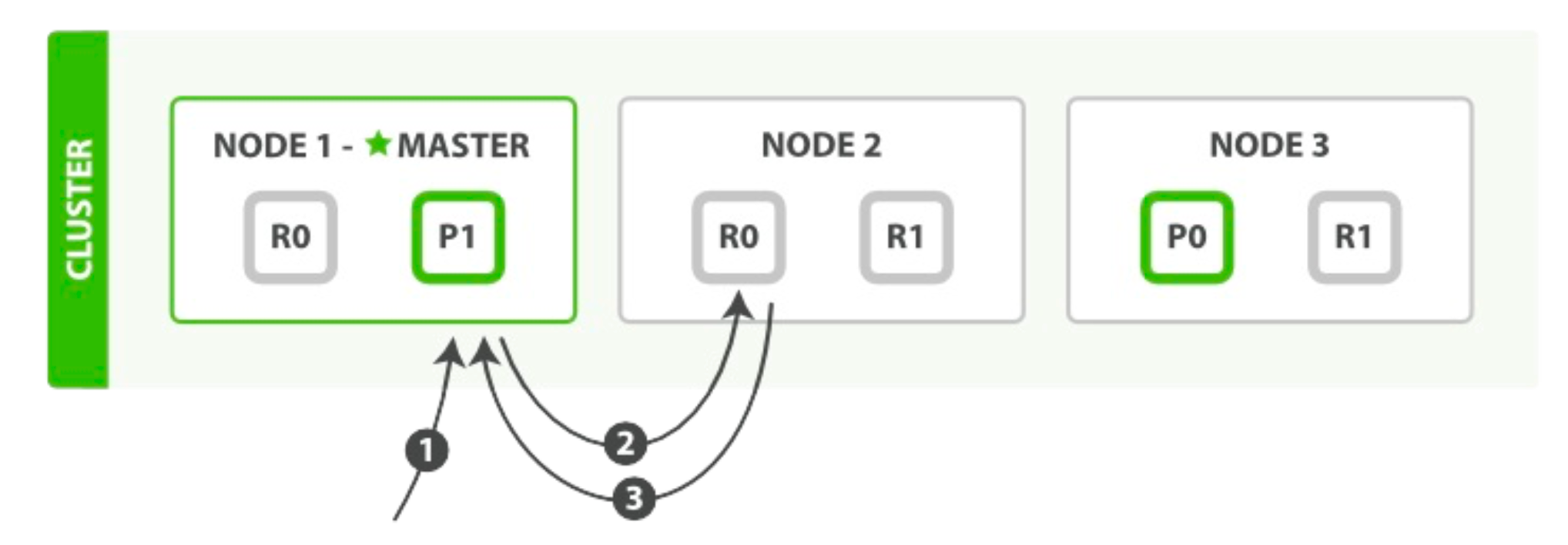
检索一个文档必要的顺序步骤:
- 客户端给 Node 1 发送get请求。
- 节点使用文档的 _id 确定文档属于分片 0 。分片 0 对应的复制分片在三个节点上都有。此时,它转发请求到 Node 2 。
- Node 2 返回endangered给 Node 1 然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。
可能的情况是,一个被索引的文档已经存在于主分片上却还没来得及同步到复制分片上。这时复制分片会报告文档未找到, 主分片会成功返回文档。一旦索引请求成功返回给用户,文档则在主分片和复制分片都是可用的。
6. 局部更新文档
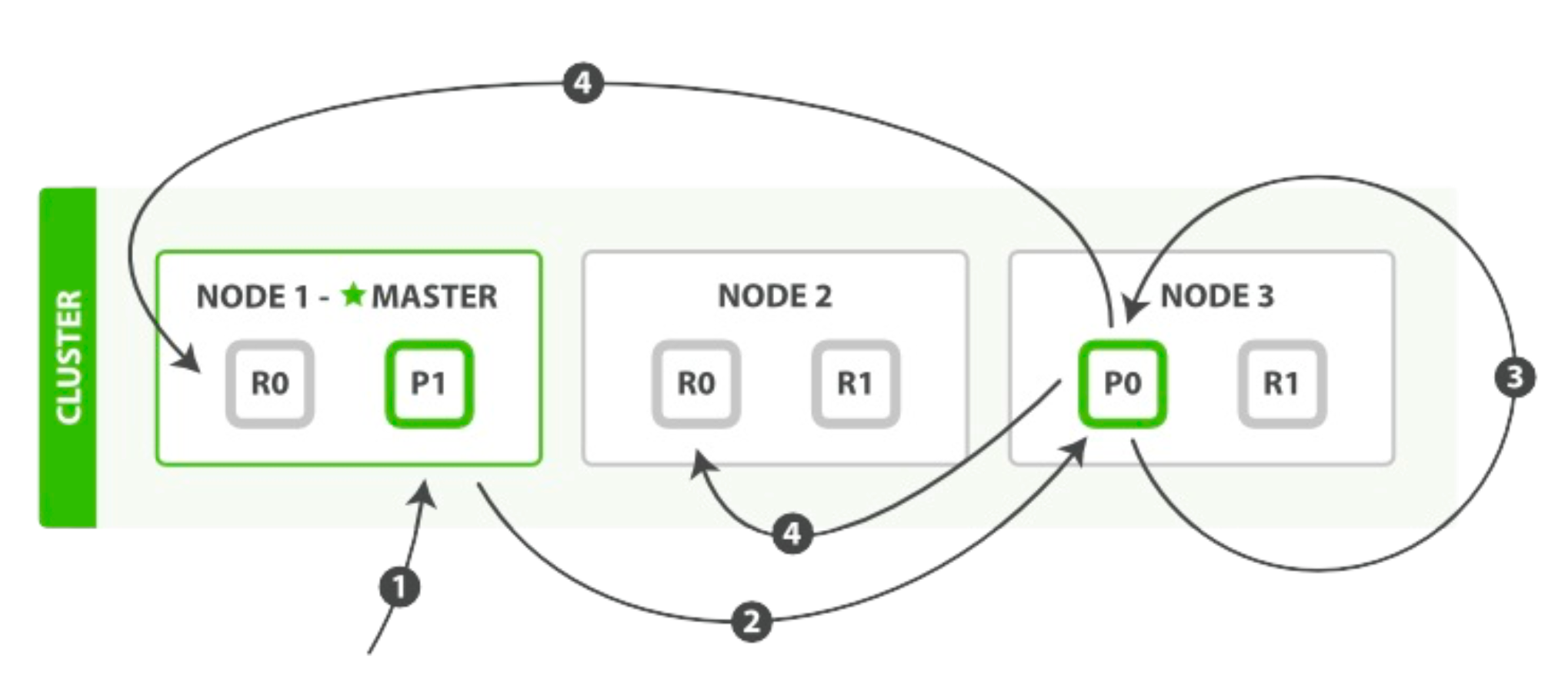
局部更新必要的顺序步骤:
- 客户端给 Node 1 发送更新请求。
- 它转发请求到主分片所在节点 Node 3 。
- Node 3 从主分片检索出文档,修改 _source 字段的JSON,然后在主分片上重建索引。如果有其他进程修改了文档,它以 retry_on_conflict 设置的次数重复步骤3,都未成功则放弃。
- 如果 Node 3 成功更新文档,它同时转发文档的新版本到 Node 1 和 Node 2 上的复制节点以重建索引。当所有复制节点报告成功, Node 3 返回成功给请求节点,然后返回给客户端。
7. 批量请求(多文档模式)
mget 和 bulk API与单独的文档类似。差别是请求节点知道每个文档所在的分片。它把多文档请求拆成每个分片的对文档请求,然后转发每个参与的节点。
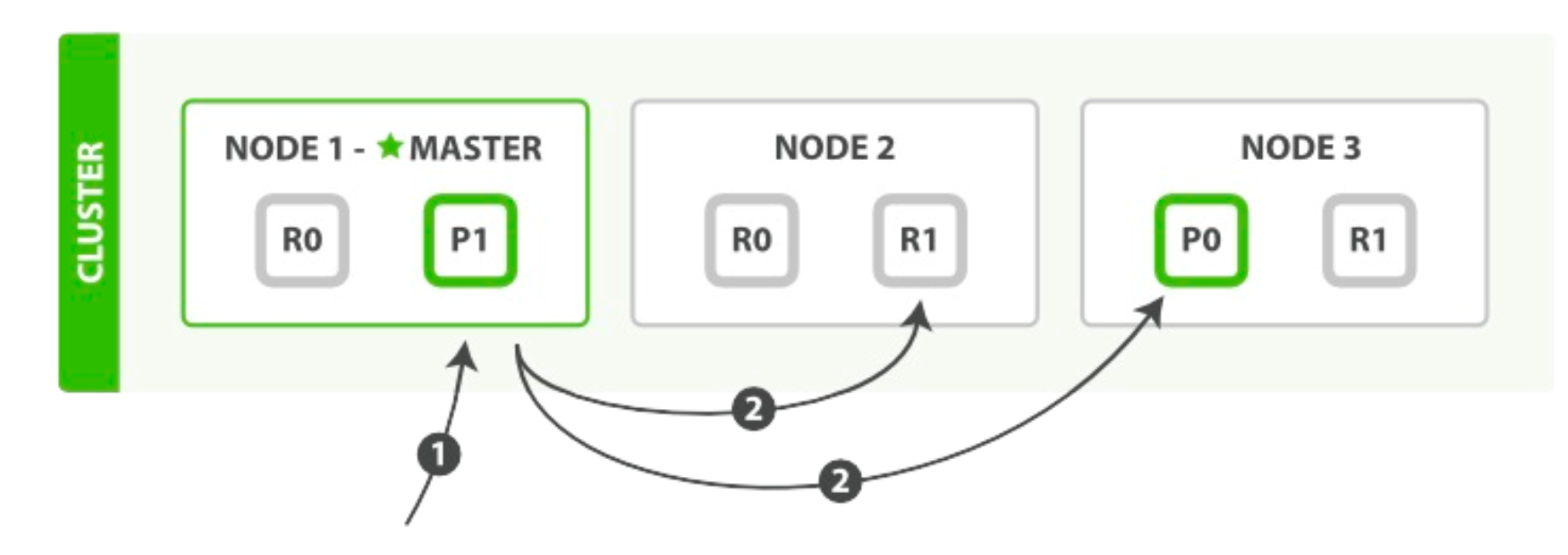
mget 请求检索多个文档的顺序步骤:
- 客户端向 Node 1 发送 mget 请求。
- Node 1 为每个分片构建一个多条数据检索请求,然后转发到这些请求所需的主分片或复制分片上。当所有回复被接收, Node 1 构建响应并返回给客户端。
bulk 执行多个 create 、 index 、 delete 和 update 请求的顺序步骤:
- 客户端向 Node 1 发送 bulk 请求。
- Node 1 为每个分片构建批量请求,然后转发到这些请求所需的主分片上。
- 主分片一个接一个的按序执行操作。当一个操作执行完,主分片转发新文档(或者删除部分)给对应的复制节点,然后 执行下一个操作。复制节点为报告所有操作完成,节点报告给请求节点,请求节点整理响应并返回给客户端。
- 阅读参考与《elasticsearch权威指南》
- 原文作者:devhg
- 原文链接:https://ihui.ink/post/elasticsearch/distributed-op/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。